How we fixed outdated AI models
In 2024, we struggled with AI models lacking access to the latest documentation when generating code for Python libraries or external APIs.
We tried creating a database of integrations, but with thousands of evolving APIs and over 608,000 Python packages, it was impossible. To solve that, we created an ai agent that goes online and searches for the latest documentation before generating code – and it worked great! We’ve also added an enormous amount of updates in the last 3 months – you can try it out for free here.
Real-World Applications of AI:
Python became the most popular language in 2024, which is unsurprising since most of the data science community uses it. There are a lot of different use-cases for Python & AI, but these are my favorite ones:
1. Document Understanding
As an engineer, extracting structured data from documents has been one of the most difficult problems I’ve worked on. Previously, you had to use OCR and write custom code to handle each document type—and even then, it didn’t work well in most cases.
GPT-4o changed that. You can now pass any document to it, and it will return the JSON representation of that document without any extra work. GPT-4o and 4o mini work great, but you can further fine-tune the vision model to achieve better results.
The ability to transform unstructured data, such as text, images, or audio, into structured data is one of the most important features of LLMs.

2. Generating & Editing Documents
When automatically generating documents such as invoices, contracts, sales proposals, and work orders, I’ve primarily used the Adobe Document Generation API (I haven’t found a better way to do this yet). The process involves creating a Document Template with {template tags} and passing a JSON object during execution.
Editing existing documents is a bit more complex – simply recreating the document is typically the way to go (Extract text > change it > create new document).
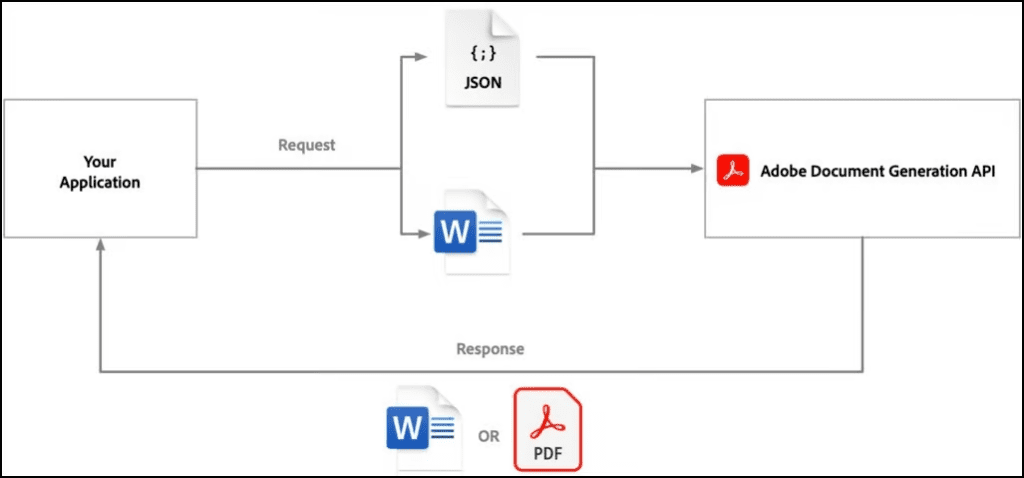
If you need to blur specific parts of a text (e.g., PII), the process involves the following steps:
- Extract the location of each word using traditional OCR methods.
- Use an LLM to detect PII.
- Finally, use the Python Pillow library to blur the identified parts of the document.
3. Data Scraping: Python, APIs and BrightData
Web scraping is often done with Python, and specifically libraries like Beautiful Soup and selenium. There are multiple ways to scrape lots of pages at the same time. (I’ll write a lot more on this topic)
One of my favorite products is brightdata.com – it’s a service that makes it really easy to get any data from almost any website. That includes social media, e-commerce, job sites, news outlets, marketplaces (even app stores like Apple/Google play).
Examples of what they can do:
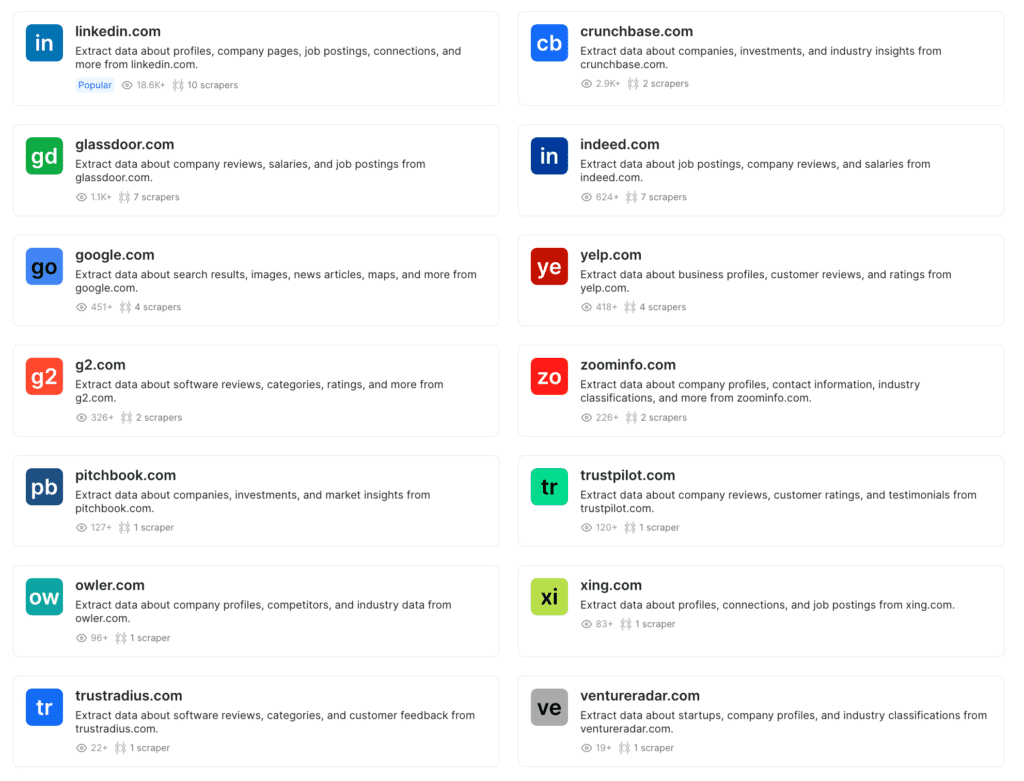
Manually scraping data from certain websites (like linkedin or facebook) is incredible difficult, and DataBright provides an easy way to get a lot of structured data easily. They charge $0.0015 per record. I personally use Trudo to set up pipelines – it works great, easy to set up and deploy.
4. Spreadsheets, CSV & JSON
Once you have all the data, Python provides libraries like pandas and numpy that make it incredibly easy to work with structured data such as spreadsheets, CSV files, and JSON files. These libraries offer powerful tools for data manipulation, cleaning, analysis, and visualization. They are particularly useful in the following areas:
- E-commerce and Retail: Customer segmentation, sales forecasting, and inventory optimization.
- Finance and Banking: Transaction data analysis, reconciliation or risk analysis.
- Manufacturing: Production planning, inventory tracking and cost optimization.
* We specifically designed Trudo to handle any amount of data with ease. Each node can process up to 10 gigabytes of data and run for up to 15 minutes.
5. OpenAI Batch Jobs: 50% lower costs + higher rate limits
If you want to process a large amount of records, you can use OpenAI’s Batch API endpoint to avoid hitting rate limits. This approach costs 50% less and the results are returned within 24 hours (and often more quickly) and supports up to 50,000 records per request.
If you need to process a large number of documents, text inputs, or embeddings at once, Batch API is a great way to do it.
If you’d like to schedule a quick demo call or have a question/suggestion, feel free to schedule a quick demo call.